14 Conclusion
This is a pre-release of the Open Access web version of Veridical Data Science. A print version of this book will be published by MIT Press in late 2024. This work and associated materials are subject to a Creative Commons CC-BY-NC-ND license.
Whether you arrived here by skipping ahead or you dedicatedly read every single word of this book, congratulations on making it to the end! It’s now time to bring this book to a close, with a summary of the primary themes and takeaway messages that we hope you have now embraced after finishing this book.
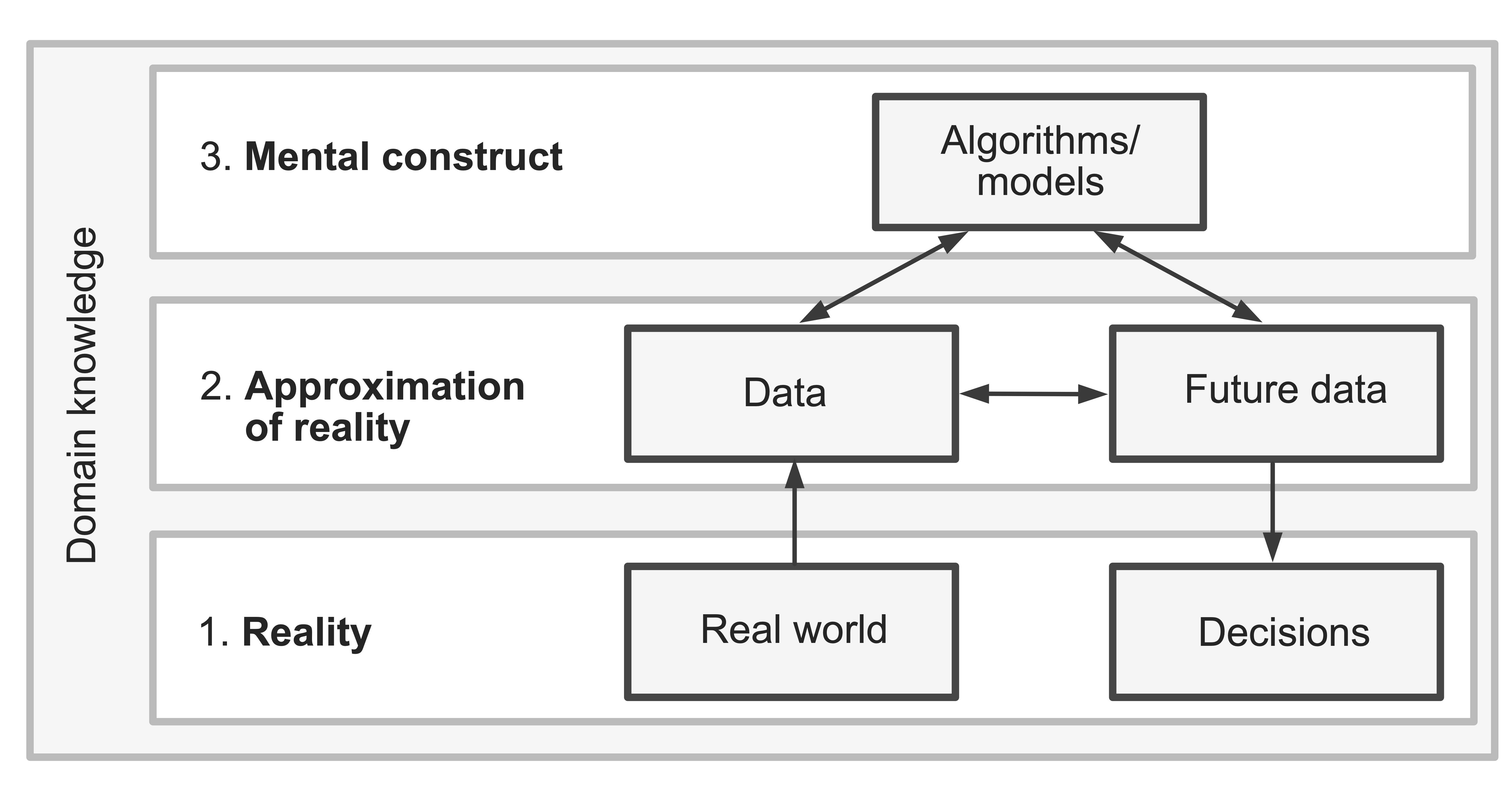
There is a wealth of useful information hidden within data, but no dataset perfectly reflects the real world. Using this hidden information to make real-world decisions can thus be problematic if we don’t take the time to understand the relationship (or lack thereof) between the data and reality, as well as how the choices that we make throughout our analyses (starting with problem formulation and data cleaning) can affect—and even distort—our conclusions. The three realms, reproduced in Figure 14.1, serve to remind us that data is never a perfect reflection of reality and our analyses will never perfectly capture the underlying real-world trends.
Fortunately, the predictability, computability, and stability (PCS) framework and documentation that we have introduced and used throughout this book can help us strengthen the connections between the three realms in Figure 14.1 by allowing us to analyze our data to solve a domain problem and transparently evaluate our data-driven results with a critical eye. By computationally showing that our results are predictable and stable and by backing up our decisions and conclusions with domain knowledge, we are providing evidence of whether our data-driven conclusions (and subsequent real-world decisions) are trustworthy and relevant to reality.
This chapter will wrap up this book with a recap of the fundamental PCS principles and a summary of the future directions of veridical data science.
14.1 Predictability
Most data science projects involve solving a domain problem by training a data-driven algorithm—or arriving at a data-driven conclusion—using a particular set of observations. However, the goal of these projects is often not to simply learn about the data we have already collected, but rather to use our algorithms and conclusions to learn about new (related, but not identical) situations. Unfortunately, since the world around us is ever-changing, there is no guarantee that the algorithms and conclusions that we have developed using one set of data (collected in the past) will remain relevant when applied to new scenarios (in the future).
Recall the example of facial recognition software that was trained primarily using images of people with light skin (Khalil et al. 2020). Likely, the engineers who trained these algorithms did not intend for their algorithm to solely be able to recognize the faces of light-skinned people; instead, their target audience was a general population consisting of people with a wide range of skin tones. However, when the training data that they used to train their algorithm did not represent the future data to which their algorithm was later applied, the result was an algorithm that was substantially more accurate for people with lighter skin (who more closely reflected the training data) than for people with darker skin (who did not). Their algorithm did not satisfy the PCS principle of predictability in the context of applying it in the future to people with a wider range of skin tones.
If the data scientists who developed this algorithm had taken the time to consider how it was going to be applied in the real world and had thus evaluated their algorithm using a much more diverse set of people (that better represent the population to which it is going to be applied), they may have been able to modify their algorithm to mitigate the bias or they may have retrained it using a dataset that more accurately reflected the future population of interest. Or perhaps they would have decided not to use the algorithm at all. The key to ensuring that data-driven results are predictable is having a realistic understanding of how they will be applied in the real world, and subsequently ensuring that the performance evaluations are reflecting the real-world domain problem.
Unfortunately, we don’t often have the resources to obtain data from relevant future scenarios to use for evaluation. We thus often instead aim to approximately satisfy the predictability principle by evaluating our results on validation and test sets that serve as reasonable surrogates of future data. For instance, even if the original data on which the facial recognition software was based was not particularly diverse, if the researchers realized that their software was going to be applied to people with a broader range of skin tones than was present in their data, they might have chosen to withhold validation and test set images that were more diverse (in terms of skin tones) than the remaining training images. While not perfect (the diversity in the withheld validation and test sets may not be nearly as broad as in the actual future data to which the algorithm will be applied), this approach would at least provide the researchers with a sense of how predictable their software is when it is applied to a more diverse set of images than it was trained on. In the absence of actual future data, PCS therefore serves as a powerful internal validation technique based on data that comes from the same source as the original training dataset, but it cannot serve as external validation for actual future data.
14.2 Stability and Uncertainty
Recall that there is rarely only one correct answer to a data-driven question. The data on which we base our results correspond to just one potential snapshot of reality, but if our data had captured a slightly different snapshot (e.g., if the data had been collected by a different person, on a different day, or using a different instrument), our results would probably look slightly different.
While it is common in traditional statistics to ask how our results might look different had a different random sample been collected assuming a particular data collection mechanism (represented using a stochastic or probabilistic “data generation model”), in veridical data science, we consider how our results might look different across a much broader set of alternative scenarios. For example, how might our results look different if we had cleaned or preprocessed the data differently or if we had used a different algorithm?
The goal of a PCS stability analysis is to try to explore as many relevant sources of uncertainty as possible. While it would be impossible to explore all sources of uncertainty associated with our results, our goal is to at least consider a substantially broader range of sources of uncertainty than just the random sampling that is considered in traditional statistical inference.
Although we are among the first to begin to meaningfully formalize the expansion of uncertainty evaluations beyond the simple data sampling mechanisms of traditional statistics, we are not the only ones paying attention to this “hidden universe of uncertainty.” In 2022, the researchers Nate Breznau, Eike Mark Rinke, and Alexander Wuttke sought to determine whether, given identical data, 73 independent research teams would arrive at the same answers to the following research question of whether “more immigration will reduce public support for government provision of social policies” (Breznau et al. 2022). Do you think that the 73 teams converged on similar results? Quite the opposite. In fact, the conclusions ranged from large negative to large positive effects of immigration on social policy support.
How could such a diverse array of answers have arisen? If you’ve arrived at this final chapter because you have actually finished reading this book, you may have some ideas. The primary reason is that, despite analyzing the same dataset, each team made a completely different set of seemingly minor judgment calls based on their own members’ expertise, background education, and assumptions. As a result, each team arrived at a unique conclusion that is a function of their own personal assumption-fueled process. Breznau et al. describe this phenomenon as follows: “Researchers must make analytical decisions so minute that they often do not even register as decisions. Instead, they go unnoticed as nondeliberate actions following ostensibly standard operating procedures. Our study shows that, when taken as a whole, these hundreds of decisions combine to be far from trivial.” The authors conclude that “variability in research outcomes between researchers can occur even under rigid adherence to the scientific method, high ethical standards, and state-of-the-art approaches to maximizing reproducibility… even well-meaning scientists provided with identical data and freed from pressures to distort results may not reliably converge in their findings because of the complexity and ambiguity inherent to the process of scientific analysis.” This research article, “Observing Many Researchers Using the Same Data and Hypothesis Reveals a Hidden Universe of Uncertainty” (Breznau et al. 2022), published in PNAS, is full of interesting insights and is well worth a read.
Like Breznau et al.’s study, one of the key takeaways of this book has been highlighting the previously hidden impacts of the judgment calls that we make when conducting data analyses. For each of the projects in this book, we tried to document (in our code files and PCS documentation) all the judgment calls and assumptions that we made. However, even with our best attempts, there were undoubtedly many judgment calls and assumptions that we made without even realizing that we made them. Given the same data and tasked with answering the same question as us, but without seeing how we conducted our analysis (or, honestly, even if you did see how we conducted our analysis), chances are that you might have conducted your analysis differently from us, and might therefore arrive at different conclusions as a result.
If your conclusions don’t match ours, does that mean that your conclusions are wrong (after all, our analysis has been written up in this very official book written by “statistical experts”)? Not necessarily: rather than indicating that one of us is wrong, the differences in our results might instead simply be a reflection of the uncertainty that is inherent in all data-driven results, in this case stemming from the judgment calls that both you and we made differently.
By documenting our analytic process, assumptions, and judgment calls (that we are aware of making) as transparently as possible in our code and documentation files, we are at least making it as easy as possible for anyone wishing to interpret our conclusions to see how we arrived at them. However, knowing how we obtained our results doesn’t tell you how our results might have been different had we collected different data or made different judgment calls when processing and analyzing it. This is why we conduct stability assessments, which allow us to actively investigate how much our results would change if we collected different data, made different judgment calls, or used alternative algorithms.
In this book, we primarily considered three sources of uncertainty: uncertainty in the set of observations that were collected; the cleaning/preprocessing judgment calls that we made; and the choices of algorithm/analysis. However, there are many others, such as the uncertainty arising from the specific person conducting the analysis (if another equally qualified person conducts the analysis instead, do they get the same answer as you?); the uncertainty arising from the specific way that the problem has been formulated (if you redefined “patient readmission” as returning to the hospital within a month or a year, do your conclusions change?); the uncertainty stemming from the particular version of software used to implement an algorithm (if you used the “randomForest” R package instead of the “ranger” R package, do you get the same results?); the uncertainty stemming from our choice of visualization techniques (if you use a bar chart versus a line chart, does your takeaway message stay the same?); and the list goes on.
Our goal isn’t necessarily to investigate all possible sources of uncertainty (this would be impossible, not to mention very tiresome). Our goal is instead to make a reasonable effort to investigate at least some of the sources of uncertainty that are likely to affect our results, such as the uncertainty arising from the data collection process, our cleaning/preprocessing judgment calls, and our algorithmic choices. Uncertainty in data science is unavoidable: even deciding on which sources of uncertainty to investigate involves making human judgment calls! While we can’t remove judgment calls from the equation entirely, we can ensure that the judgment calls that we do make take into account domain knowledge, as well as constraints on both human and computing resources.
14.3 Future PCS Directions: Inference
What’s next for the PCS framework? You may have noticed that this book did not cover the topic of inference (the traditional statistical topic of assessing the uncertainty associated with parameter estimates, usually focusing on the random sampling mechanism). While we did conduct a type of PCS inference in the context of continuous response prediction problems, such as by computing prediction perturbation intervals (PPIs), we did not discuss p-values, hypothesis tests, confidence intervals, or causality.
Rest assured that the reason for this omission is not that these topics are not important, but rather that these topics become quite complex when considered in the realm of PCS, and are thus topics of ongoing research in the Yu research group. Besides, one book cannot possibly cover everything!
In traditional statistics, inference is the science of quantifying the uncertainty associated with data-driven results. However, traditional inference usually considers only the narrow view of uncertainty that arises from a random sampling data collection mechanism (or from a generative stochastic model that is typically difficult to verify for real-world data). As we’ve established by now, the uncertainty that stems from cleaning/preprocessing judgment calls, as well as the analysis/algorithmic choices, can be substantial (often greater than the uncertainty arising from the data collection alone, as emulated via random sampling). By ignoring these sources of uncertainty, traditional inference techniques are taking into account only a small sliver of the uncertainty associated with parameter estimates. The end result is typically an excess of “significant” results being identified.
PCS inference, an ongoing area of research development in the Yu research group, aims to bring broader sources of uncertainty into inferential assessments. Soon you will be able to compute PCS importance measures, PCS p-values, and PCS perturbation intervals that quantify a wide range of the sources of uncertainty that are associated with any data-driven result, not just the uncertainty arising from random sampling (Yu and Kumbier 2020). (Keep an eye out for research developments from the Yu research group!)
The expansion of veridical data science and the PCS framework is not limited just to inference. There are also several emerging domain-specific branches of veridical data science originally inspired by the original “Veridical Data Science” paper by Yu and Kumbier (2020), including veridical spatial data science (Kedron and Bardin 2021), veridical network embedding (Ward et al. 2021), and an extension of the PCS framework to reinforcement learning (Trella et al. 2022).
14.4 Farewell
Equipped with a reality-based and domain-grounded veridical data science perspective, you’re now ready to tackle any data science project that comes your way. Remember that the veridical data science PCS principles can be applied to every single data science project, extending far beyond the examples presented in this book. Together, let’s enter a world in which every data-driven result that is used to make real-world decisions is predictable, computable, stable, and, above all, trustworthy.
References
Breznau, Nate, Eike Mark Rinke, Alexander Wuttke, Hung H. V. Nguyen, Muna Adem, Jule Adriaans, Amalia Alvarez-Benjumea, et al. 2022. “Observing Many Researchers Using the Same Data and Hypothesis Reveals a Hidden Universe of Uncertainty.” Proceedings of the National Academy of Sciences 119 (44).
Kedron, Peter, and Sarah Bardin. 2021. “A Vision for Veridical Spatial Data Science.” In Spatial Data Science Symposium 2021 Short Paper Proceedings.
Khalil, Ashraf, Soha Glal Ahmed, Asad Masood Khattak, and Nabeel Al-Qirim. 2020. “Investigating Bias in Facial Analysis Systems: A Systematic Review.” IEEE Access 8: 130751–61.
Trella, Anna L., Kelly W. Zhang, Inbal Nahum-Shani, Vivek Shetty, Finale Doshi-Velez, and Susan A. Murphy. 2022. “Designing Reinforcement Learning Algorithms for Digital Interventions: Pre-Implementation Guidelines.” Algorithms 15 (8): 255.
Ward, Owen G., Zhen Huang, Andrew Davison, and Tian Zheng. 2021. “Next Waves in Veridical Network Embedding.” Statistical Analysis and Data Mining: The ASA Data Science Journal 14 (1): 5–17.
Yu, Bin, and Karl Kumbier. 2020. “Veridical Data Science.” Proceedings of the National Academy of Sciences 117 (8): 3920–29.